Chez iiiData, on a fait le choix de l’open-source au maximum pour toute notre stack technique. A mon tour aujourd’hui de vous parler de l’outil qui nous occupe bien depuis plusieurs mois avec Martin pour récupérer des données, à savoir Airbyte.
Ben oui, on hâte de vous parler de nos modèles de Data Science qui vont (sans aucun doute …) révolutionner le monde de la Data Science mais pour l’instant, on est dans la phase de collecte des données, d’où AIRBYTE !
MAIS C'EST QUOI CE AIRBYTE?
Airbyte est un outil open-source permettant de faire de l’intégration de données. Vous connaissez sans doute les outils type ELT ou ETL (E pour Extraction, L pour Load ou chargement des données et T pour Transformation des données). Ici, on a un outil puissant qui « Extrait » et « Load » nos données. La partie Transformation sera assurée par DBT, dont on vous parlera dans des articles à suivre…
Le concept d’Airbyte est né en 2020 et actuellement en novembre 2022, l’outil met à votre disposition plus d’un millier de connecteurs possibles, de type source ou destination.
L’un des grands avantages d’Airbyte est que l’on peut développer son connecteur, s’il n’existe pas encore, via le « Connector Development Kit » qui fera l’objet de plusieurs articles à suivre.
Objectif de ce tuto
Aujourd’hui, le but de cet article est de vous présenter les bases d’Airbyte, via la mise en place d’un connecteur récupérant des données stockées dans un fichier plat que l’on veut enregistrer dans une base PostgreSQL.
Si vos données sont propres et ne nécessitent pas de transformation, l’étape d’après, c’est de la Data Viz. Nous avons fait le choix d’explorer Streamlit chez iiiData donc rdv ici avec les articles de Martin sur Streamlit.
Comme c’est très souvent le cas pour les projets open-source, on retrouve le code source d’Airbyte sur GitHub, ici : https://github.com/airbytehq/airbyte et on peut le déployer sur Docker.
Pour en savoir plus, Airbyte a détaillé les prérequis techniques ici.
Une fois Docker installé, le plus simple est de cloner ce projet en local :
Pour la 1ère connexion, vous pouvez ajouter votre e-mail, choisir vos préférences de collecte de données, …
Mon 1er connecteur : fichier plat sur SFTP
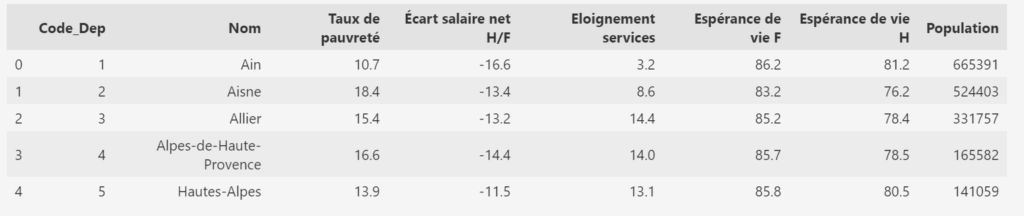
Chez iiiData on travaille beaucoup sur des open-data territoriales donc je vous propose de ré-utiliser le fichier CSV issu du site de l’INSEE que Martin a préparé pour nous.
Voici un petit aperçu ci-dessous et si vous voulez avoir un rapport complet des données de ce fichier, je vous encourage vivement à lire l’article sur Pandas-Profiling.
Dans la page d’accueil d’Airbyte, vous retrouvez en haut à gauche les boutons permettant d’accéder à :
les connections : combinaison d’une source et d’une destination
les sources
les destinations
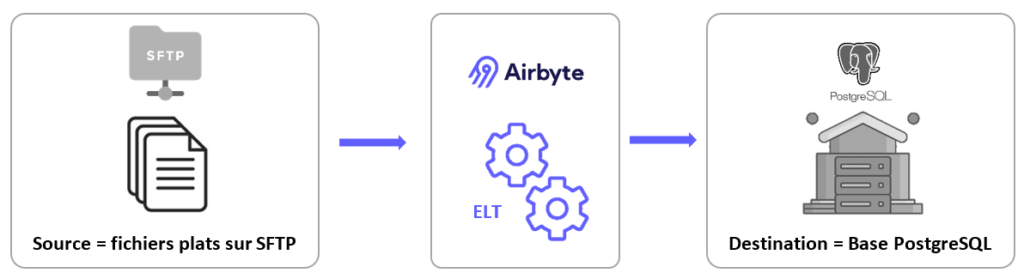
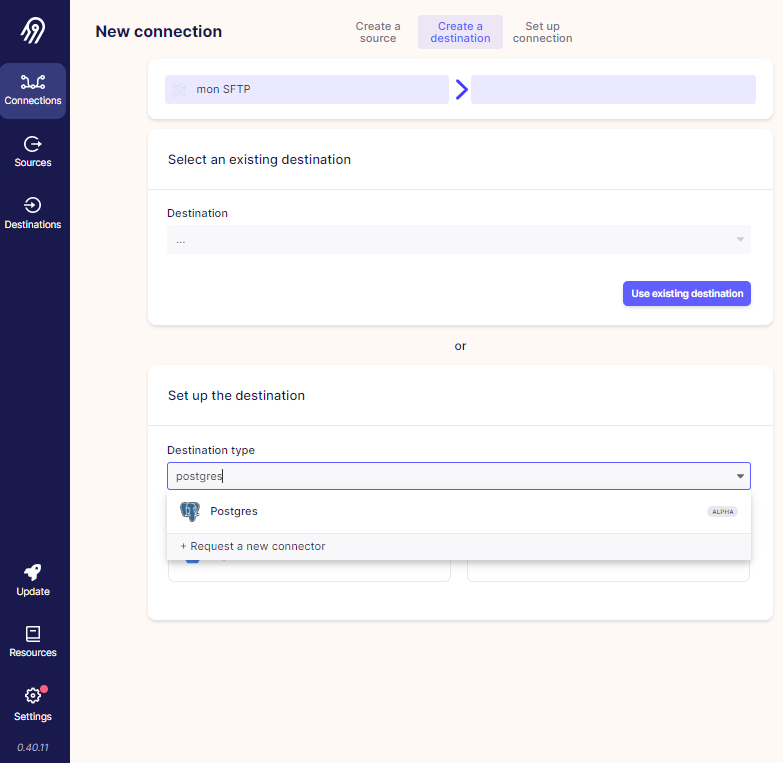
Ici, nous allons créer un 1er connecteur qui aura pour source un SFTP sur lequel récupérer les fichiers plats souhaités et qui stockera les infos dans une destination de type base PostgreSQL en local.
Ci-dessus, une petite démo du processus à suivre.
Ci-dessous les étapes détaillées avec des explications :
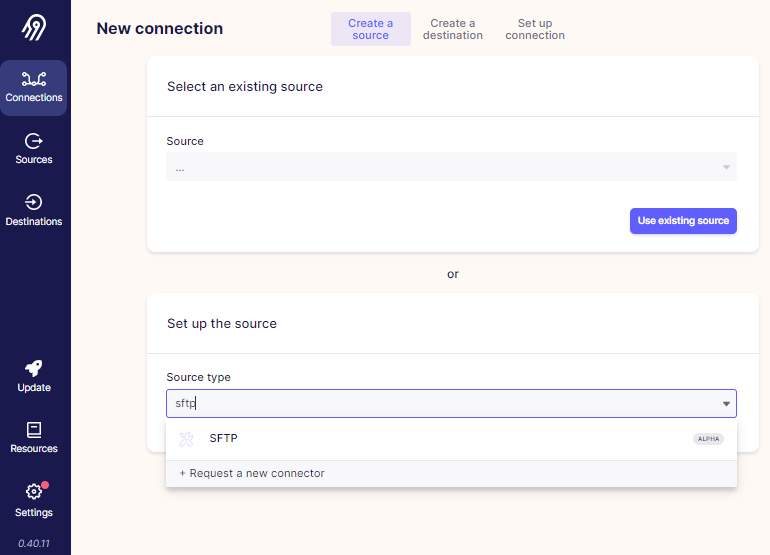
ETAPE 1 : On clique sur "Connections", puis sur "New connection" (en haut à droite)
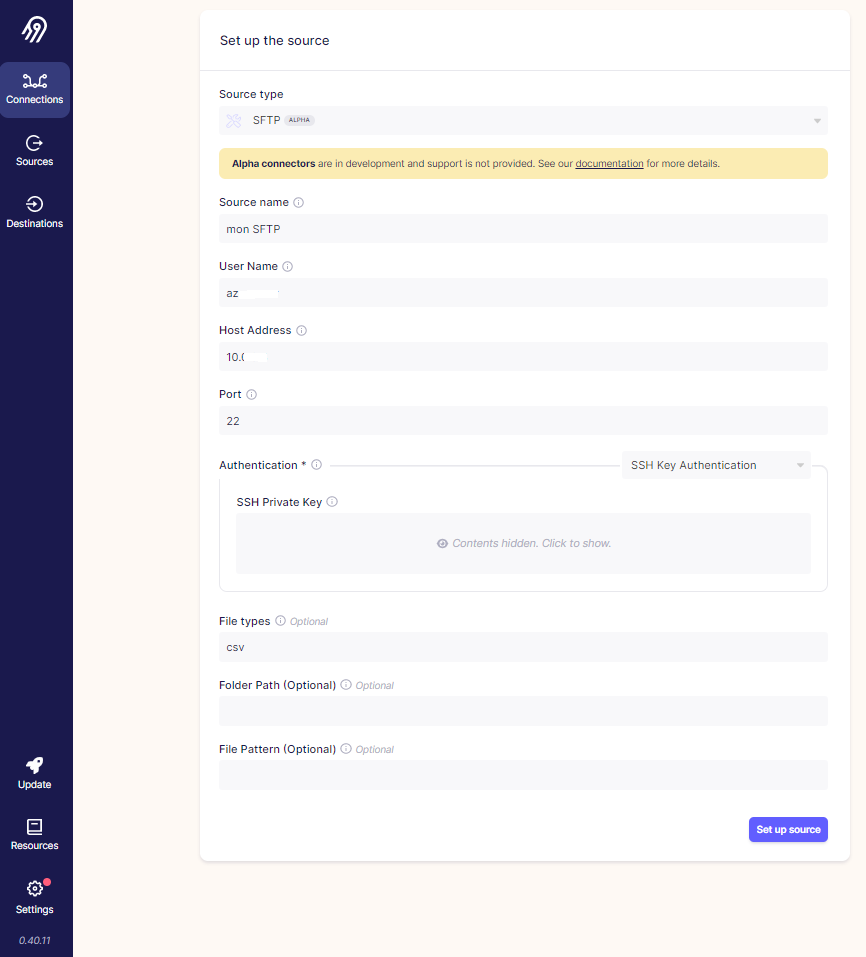
ETAPE 2 : on définit les paramètres du SFTP
ETAPE 3 : on choisit la destination souhaitée, ici une base PostgreSQL.
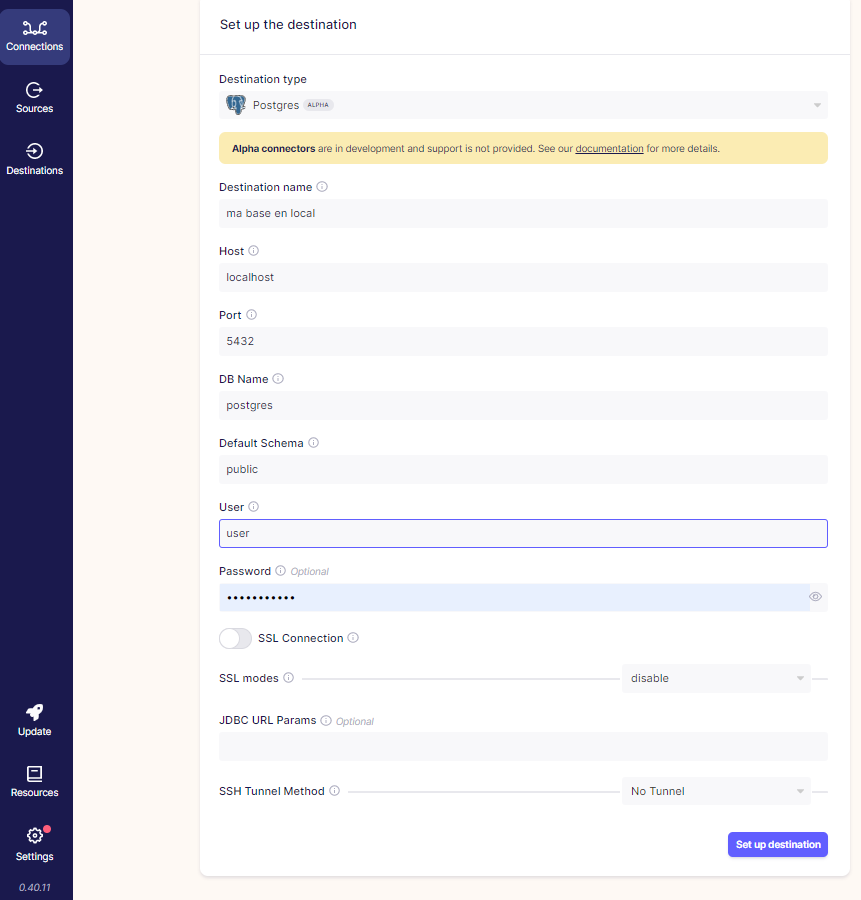
ETAPE 4 : on définit les paramètres de la base PostgreSQL en local.
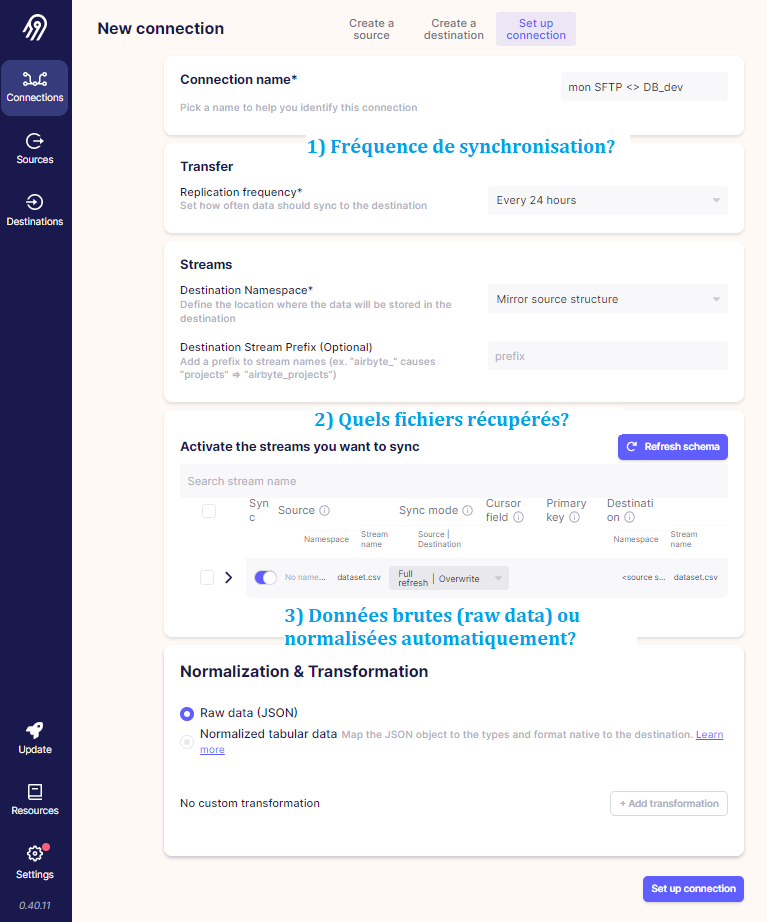
ETAPE 5 : on affine les paramètres, avec un 1er aperçu des fichiers récupérés
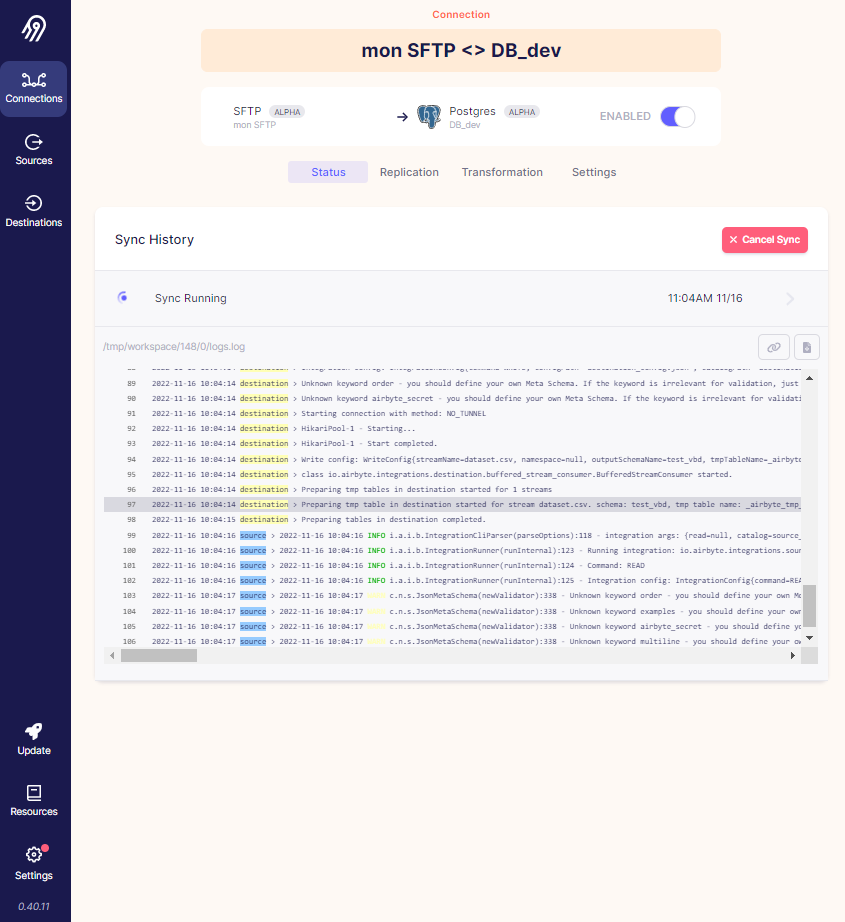
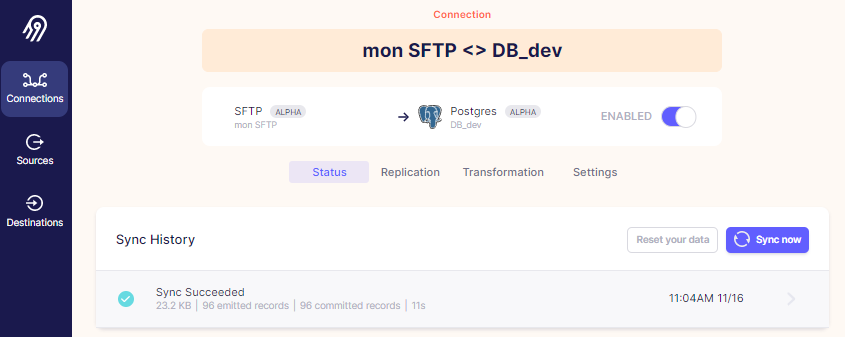
Etape 6 : Aperçu des données en cours de récupération avec les logs qui s'affichent en simultanée.
THE END...
Normalisation par Airbyte ou données brutes ?
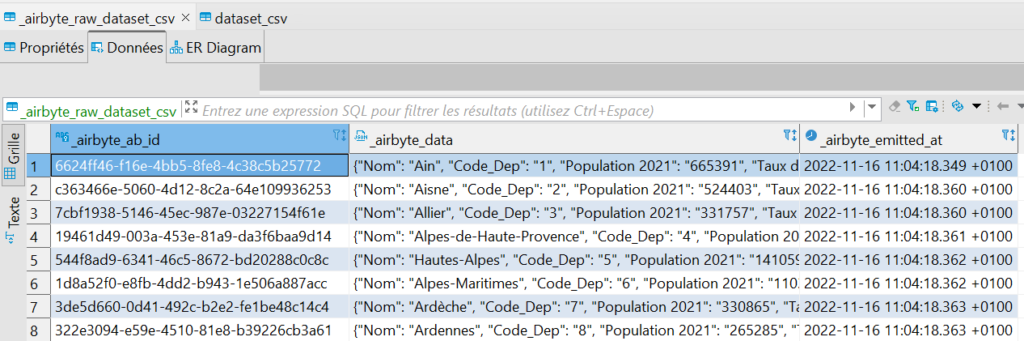
Et voici un aperçu de ces données brutes dans la base :
Données en mode "Raw Data", soit 2 colonnes créées par Airbyte et une colonne "_airbyte_data" contenant un JSON
Si vous choisissez à l’étape 5, l’option « Normalized tabular data », Airbyte créera une table avec les données au format brut, comme vu précédemment et une ou plusieurs tables détaillant les fichiers JSON de la colonne « _airbyte_data », en fonction de l’arborescence du schéma JSON.
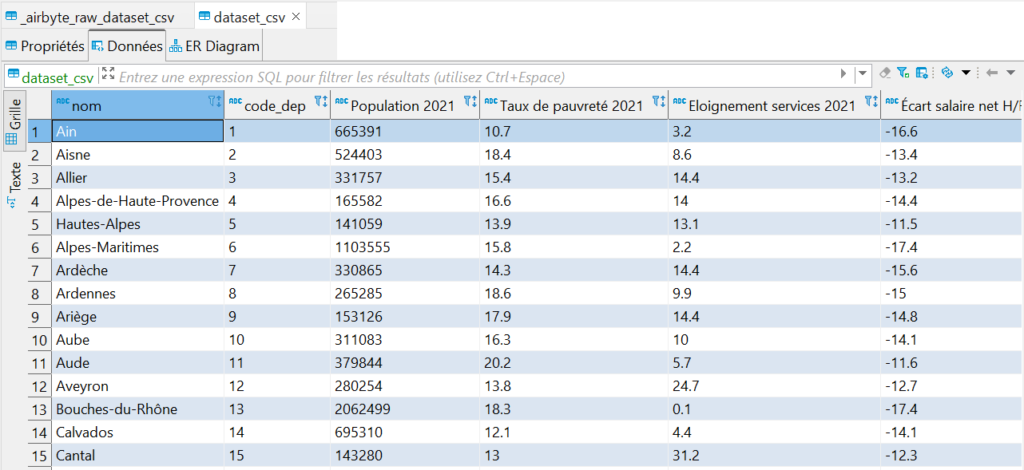
Voici un exemple du résultat normalisé par Airbyte :
Dans le cas d’un fichier plat, Airbyte crée automatiquement la table ci-dessus en reprenant la forme tabulaire vue initialement.
Lorsque le résultat d’une extraction produit un fichier JSON plus complexe, la normalisation automatique peut être un choix intéressant que nous détaillerons dans un prochain article.
En savoir plus?Nous prévoyons d’écrire une série d’articles dans les semaines à venir sur Airbyte mais en attendant, nous serons ravis si tu nous laisses un commentaire sous cet article ou sur LinkedIn.
Par ailleurs, Airbyte est un outil récent mais avec une communauté très dynamique, donc quand il y a un problème, on fouille sur leur slack ou on explore les tutos déjà parus sur leur site web.
EN bref, l'outil ELT parfait?
Après plusieurs mois d’essai, le choix d’Airbyte dans notre stack est confirmé :
le choix des connecteurs intégrés est vaste
la création de connecteurs customs n’est pas simple mais donne des résultats très intéressants
la communauté est très active et sort de nouveaux connecteurs, chaque semaine
la doc est fournie, pas assez détaillée mais elle a le mérite d’exister et les tutos proposés sont très documentés.
Bien sûr, Airbyte n’est pas parfait mais c’est un outil très prometteur et en pleine expansion que nous avons choisi d’inclure notre stack technique iiiData.
Des points faibles?
problème de stabilité et de maturité : mieux vaut être dans la toute dernière version et faire des mises à jour régulières! (On s’est pris bcp de murs, en utilisant une ancienne version…)
nécessite des connaissances pointues en Python : Airbyte peut être utilisé comme un framework Python mais du coup, le temps d’apprentissage n’est pas anodin.
Conclusion
J’espère que ce tuto t’aura aidé à mieux comprendre les bases d’Airbyte. En tout cas, chez iiiData, Airbyte a su nous séduire et nous avons très envie de continuer à écrire sur le sujet donc rdv dans quelques semaines pour la suite…
Bien sûr, nous serons ravis d’avoir plus d’échanges sur ce sujet via LinkedIn ou dans les commentaires de l’article, donc si tu as des suggestions d’article ou autre, tu sais quoi faire!